
Is Haystack better than LangChain?
A battle of LLM frameworks, which is better for your next RAG pipeline? Can we figure it out with the help of Chuck Norris?


As the adoption of large language models (LLMs) like GPT-4, o1, Llama, and Gemini increases, developers are turning to frameworks and higher abstractions to simplify building Gen AI applications powered by these models.
Unless you were asleep the past 2 years, you’ve probably at least heard of LangChain, a modular framework for building applications with LLMs, including RAG, chatbots, agentic workflows, and more. LangChain has grown extremely popular, with nearly 100k stars on GitHub at the time of this writing 🤩
Today, though, I want to discuss another open-source framework, Haystack, developed by a Berlin company, deepset.
First Thoughts
My first opinion of Haystack was that it is extremely simple. Now remember that statement because, in a moment, we’ll see how that could be Haystack’s kryptonite, too.
For context, I have been writing Python code for around a decade, so I had no syntax struggles with either framework. However, the semantics in Haystack had a much smaller learning curve, as everything boils down to either a component or a pipeline. This is immediately pointed out in their overview.
After a couple of hours reading the “Getting Started” docs and following a simple RAG example, I successfully implemented my own custom component to retrieve data from a REST API and integrate it with a prompt builder and LLM. Creating custom components was very Pythonic and honestly made sense even if I weren’t messing with LLMs.
That said, as I began trying to make more dynamic patterns like an agentic workflow or multi-modal applications, it felt more limiting—the pipelines were easy to adapt to linear workflows, but more organic, complex flows didn’t feel as intuitive. This may be just my lack of experience.
Comparing Customization
Pictures speak 1,000 words; code speaks 10,000 😅 Let’s see how they compare by writing a simple custom retriever in LangChain and then in Haystack:
LangChain Custom Retreiver

This is pretty straightforward, although we’re clearly just hardcoding fake documents and doing one of the most naive and inefficient searches possible.
With LangChain, we just inherit the BaseRetreiver abstract class and implement the _get_relevant_documents() method. The class uses Pydantic to model the class’s required inputs, which we only define one: documents. A more realistic retriever might implement an embedding algorithm, query a vector database, call a REST API, or even use an LLM (e.g., generate relevant questions based on the user’s query).
Haystack Custom Retriever
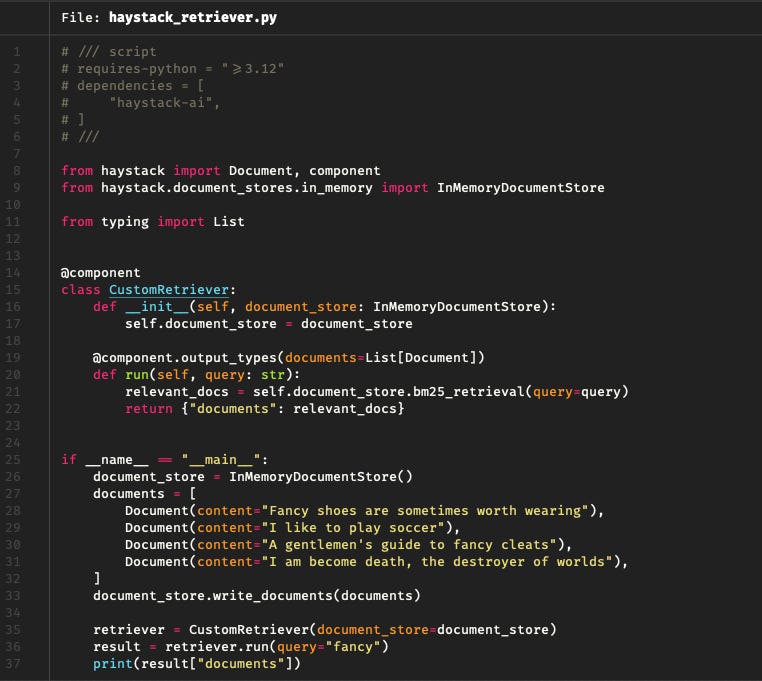
Haystack looks pretty similar, but I took the liberty of using the InMemoryDocumentStore, which has BM25, a probabilistic information retrieval model that basically uses a bag-of-words and term frequency.
With Haystack, the component is a Python class marked by the @component decorator, and a run() method.
These retrievers are not usually invoked directly; they are often part of a chain or pipeline. Let’s see another example that uses a component in a pipeline: custom prompts.
Haystack Pipelines
Okay, let’s create a more…fun, custom component. This calls the Chuck Norris joke API and returns the joke that we will then use in a pipeline to generate images 🤣

Next, you create a Pipeline, add the components, and connect them.

As you can see, this is very straightforward with Haystack. You register each component with a name and then wire them together, essentially connecting each component’s inputs and outputs.
In this example, I am pipelining the Chuck Norris API → PromptBuilder → DALL-E image generator.
Notice that I don’t connect anything in the pipeline to the style template variable; instead, I leave it empty to pass that in via the command-line arguments and change the style as I like.
Running this pipeline gave me some great laughs, and even if you hate Haystack, I recommend giving it a shot for your own fun.
Joke: When Chuck Norris break the build, you can't fix it, because there is not a single line of code left.

LangChain Chains
If I were to write this in LangChain, the simplest way would be to write custom tools with the @tool decorator, or you could use classes and subclass them from the BaseTool class provided by LangChain. Afterward, we would construct a chain, such as the SequentialChain, and provide it with a list of our tools.
I found that the process of creating a PromptTemplate in LangChain and using it between the joke generator and the image generate was strangely verbose; however, this makes sense given how LangChain is designed to be more open and caters well if you’re building agents / agentic workflows.
Final Comparison
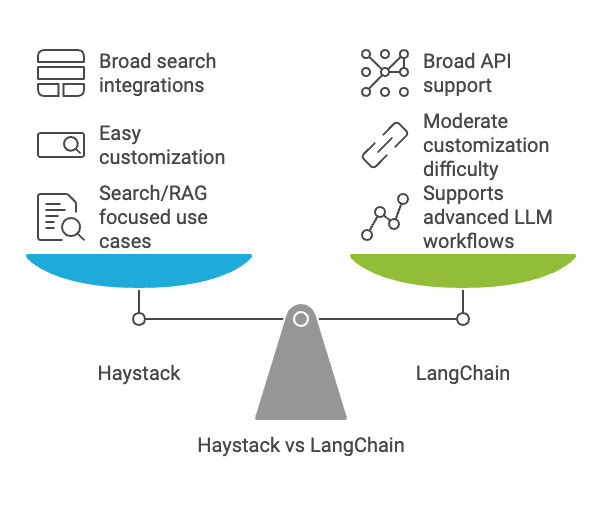
Both are very similar, but I found Haystack simpler and with an easier learning curve. Haystack would be great if you just want to get up and running fast, building applications such as RAG, Q&A, search, or general sequential workflows.
LangChain, on the other hand, has a steeper learning curve but is more robust. LangChain is better for agentic workflows and advanced concepts such as tool calling, ReAct (Reasoning and Acting), and chat memory. LangChain probably has more community tools available now, although Haystack also has tons.
At the end of the day, you shouldn’t listen to the hype about specific tools; try Haystack and LangChain out and see which one fits your needs and development style better!
🚨 Hey! I’m currently working on a personal health and fitness Haystack application that uses data from apps like MyFitnessPal, Hevy, and leading LLMs to give personal feedback and recommendations. If you’d like to see a project-based post for this in the future, be sure to subscribe!
MakeWithData is free today. But if you enjoyed this post, you can tell MakeWithData that their writing is valuable by pledging a future subscription. You won't be charged unless they enable payments.