
7 Ways to use AI for Data Products in 2025
AI isn't going anywhere! Learn how you can stay ahead of the competition and streamline business by integrating AI into your data products.

If 2024 has taught us anything, it’s that AI (generative or not) finds a home in everything we touch and use. Data is the root of AI's power, so, of course, data products are among those being enriched.
That said, much of the trends and startups were pure hype, and you either drank the Kool-Aid or played it slow with the risk of “falling behind” (seemingly, at least). The difference in 2025 will be that generative AI tools are currently in the “trough of disillusionment.” This means we can expect to see these tools mature and some of the more gimmicky offerings that are just out for a quick buck to die down.

So, as data engineers and stewards of our organization’s data, we must prepare for the pragmatic integration of AI into our data products this upcoming year. I’ll share several use cases in categories such as:
Developer Experience
Data Processing
Data Consumption
New Products
Predictive Modeling and Forecasting
Data engineers can integrate AI models into data pipelines to generate predictions and forecasts. For example, we may predict customer churn, forecast sales or website trends, and identify anomalies.
Here are some tools you can use to quickly forecast on your data:
Prophet (by Meta): Prophet is a time series forecasting library designed for handling data with seasonality. It is particularly effective for forecasting business metrics, such as sales, website traffic, and resource usage.
Apache Spark MLlib (+ Prophet): Spark MLlib is a scalable machine learning library that is integrated with Apache Spark. It provides various classification, regression, clustering, and collaborative filtering algorithms, making it suitable for building predictive models on large datasets.
Databricks ai_forecast() function:
ai_forecast()is a table-valued function in Databricks designed to extrapolate time series data into the future. Literally just a SQL function—it can’t get any easier than this.
Why: Supports proactive decision-making and detects problems sooner.
Retrieval Augment Generation (RAG) on your Data
Your data is your company’s most valuable asset—period, full stop. Many companies, even outside the tech sector, have realized this value in recent years. Gen AI has expanded this value further with the Retrieval Augmented Generation (RAG) concept, in which a large language model (LLM) dynamically retrieves data from a vector database to provide more contextual and correct answers.
As data engineers, we must start thinking about the most valuable data for this purpose. RAG isn’t limited to structured data—in fact, it is typically more valuable in unstructured data, which is traditionally more difficult to search or parse. For example, all of the following could be great candidates you could create “embeddings” for and store in a vector database:
PDF Documents (tip: check out this PDF reader for Apache Spark!)
Images/Pictures
Audio Files
Logs and other Text Files
Excel/Powerpoint/Word Documents
Of course, AI can also access your structured and semi-structured data, but you may leverage concepts like AI Tools or Function Calling to achieve that.
For RAG, here are some tools that can be used to build RAG pipelines, create and manage vector data storage, and integrate RAG with your applications:
Haystack: an open-source framework for building production-ready LLM applications, RAG pipelines, and state-of-the-art search systems that work intelligently over large document collections. Of course, there is LangChain, which you should also check out.
Databricks: Databricks offers building blocks for RAG, such as its Vector Search, serverless model serving endpoints, Tools or function-calling, AI agent evaluation, and various LLMs.
Azure AI Search: managed Azure cloud service that enables efficient searching of unstructured data, offering features like full-text search, autocomplete, and semantic ranking across various data formats and languages.
Amazon Bedrock: managed AWS cloud service supporting a variety of Foundation Models (FM) and facilitating data vectorization and vector storage.
Why: RAG opens the door to several new ways of leveraging your data alongside Large Language Models (LLMs), bringing your private data into context and improving accuracy, recency, and data lineage without requiring you to train your own model.
AI for Data Quality
Whether you’re already experienced in managing data quality or are just tackling issues as they come, AI offers clear opportunities for enhancement.
One of my favorite use cases here is using AI to automatically detect and obfuscate sensitive information automatically. Databricks has a great solution accelerator for this use case with the Protected Health Information (PHI): https://www.databricks.com/solutions/accelerators/automated-phi-removal
I’m excited about using similar features from Databricks, such as ai_classify() and ai_mask(). These simple SQL functions use generative AI to classify input text according to the labels you provide or mask things like PII, respectively.
Not to make it all about Databricks, but I have to give them kudos once more for Lakehouse Monitoring. Lakehouse Monitoring helps you monitor your data integrity, how your data changes over time, statistical distribution, drift detection, and more. More importantly, as we build AI and use AI more ourselves, we need to ensure that AI has appropriate data quality, and Lakehouse Monitoring covers this by tracking model performance/accuracy with metrics like F1 score.
Why: AI automates crucial and tedious tasks such as data monitoring, identification, tagging, and redaction. This identifies problems and secures your sensitive data quicker and more reliably.
AI for Business Intelligence - cut out the middle man!
BI is usually a back-and-forth process for data analysts and analytics engineers to maintain SQL queries, data visualizations, and business stakeholders' constant intake of different analytical questions. Wouldn’t it be nice if you could just ask the questions and create those pretty bar charts on the fly?
This is one of the most interesting AI use cases for data practitioners, and I expect we’ll see many more in 2025. Major players, such as Databricks with its AI/BI Genie and Microsoft’s Copilot for Power BI, have already begun successfully demonstrating it.
The key to this being successful will come down to the process in terms of “who” manages the tooling and “how” it is administered. Some tools, like Databricks Genie, require the setup of a “space” that is configured with data sources (tables), instructions, and example prompts/queries—these are crucial to get right, and you’ll get out of it what you put into it (effort).
Why: Business stakeholders get answers quicker and with personalized visualizations, and BI engineers can focus on managing the underlying data, its quality, prompts, and feedback loops.
Creating New Data Products with AI
While AI has many uses for increasing our productivity and internal workflows, I believe it also opens the door for us to generate new types of data products. The marketplace concept is already quite popular with cloud providers like AWS, Azure, GCP, and even leading data platforms like Databricks; these marketplaces have always been hosts of a myriad of datasets and applications, so if your organization has data that it would like to monetize it could do so easily.
AI has expanded this market with the opportunity to create AI applications or turn-key components for AI integration. Here are a few examples I can think of, some of which are already being seen:
Pre-computed Vector databases of common datasets
Fine-tuned small language models (SLMs) for targeted use cases
Data integrations for proprietary SaaS vendors: data retrievers, automated vector synchronization, function calling libraries.
Self-service for enterprise customers to access their own data via technology like Delta Sharing, as more customers seek to utilize their data from vendors in their own AI.
Why: Maximize the value of your data by capitalizing on its practicalness for AI and leveraging marketplaces to deliver and distribute.
Coding Assistants
AI coding assistants were some of the very first to take off and show significant value to engineering teams. That also makes them some of the most mature already, so if you’re not using one already—stop waiting.
Mileage may vary, but the ones I recommend the most:
Databricks Assistant: for all coding inside Databricks. Plus, it’s free!
GitHub Copilot: Although I read many negative comments about Copilot compared to some more recent startups, it’s still one of the best all-purpose coding assistants I have used, regardless of language. It also supports settings like opting out of your completions being used for product improvements (training) and disabling matching public code.
Amazon Q Developer: Perfect if your organization runs tight vendor security and only allows AWS-native services.
Why: Coding assistants produce code more quickly. No, they’re not replacing developers—they’re speeding up the more tedious aspects of coding so we humans can focus on the bigger tasks!
Fixing Errors
Interpreting error stacktraces is a vital skill for engineers when troubleshooting issues. Still, even experienced engineers may need several minutes to parse through the error, search solutions such as StackOverflow, and figure out how to apply the fix to their code.
AI can save you a ton of time by at least interpreting the error for you and often even fixing your code for you. For this reason, many coding assistants like the ones mentioned above have commands like /fix.
Pro-Tip: Databricks even has a Public Preview for its AI assistant diagnosing your failed jobs: https://docs.databricks.com/en/notebooks/use-databricks-assistant.html#diagnose-errors-in-jobs-public-preview
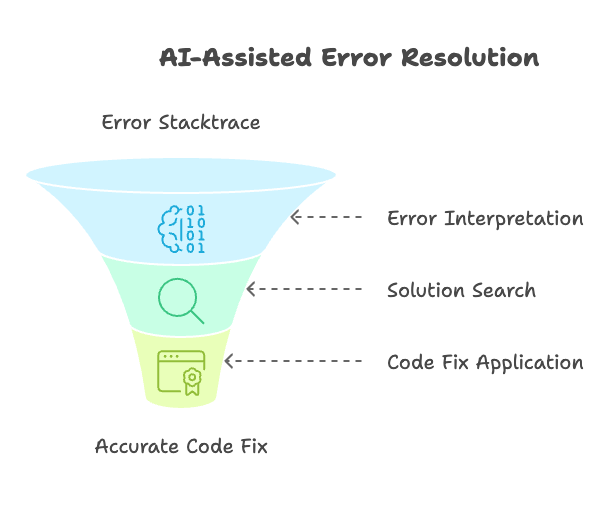
I have heard complaints that the error explanations are sometimes wrong or that the suggested fixes frequently have bugs. You can significantly improve the accuracy of these outputs by toggling whether the tool (e.g., Amazon Q or GitHub Copilot) should index your entire code workspace. This informs the assistant about your complete codebase and provides better context.
Why: Researching and fixing exceptions is faster with the help of AI. Our time is better spent actually resolving the problem, not reading 3 StackOverflow pages, some 2-year-old blog post, and scouring source code on GitHub.
Conclusion
I hope you have enjoyed these use cases and have some new ideas to integrate AI into your data engineering workflows and data products in 2025.
Remember, these tools and services are on track for maturity and true enterprise readiness, so don’t settle for less by grabbing the first thing you read about! Try some of the tools I mentioned and decide for yourself. Let me know in the comments if you recommend any other AI tools!
Also, if you don’t mind supporting the MakeWithData blog (I promise it’s really just me, an individual guy who loves to nerd out), please like this post and consider pledging for future posts below!
MakeWithData is free today. But if you enjoyed this post, you can tell MakeWithData that their writing is valuable by pledging a future subscription. You won't be charged unless they enable payments.